10 5 月, 2026,由 frank 撰写
距上次梳理阿里HPN的论文已过去2年时间了,这次看微软/OpenAI联合多家NIC/交换机厂商(NV CX-8、AMD Pollara/Vulcano、BRCM Thor Ultra、NV Spectrum 4/5、BRCM TH5)发布的 MRC + SRv6 论文,网络架构思路差异很大,但很多设计点跟HPN/UEC形成对比,值得对照仔细研究,里面很多信息可以借鉴和参考,可以说是为数不多的好论文(对我的领域而言)。从目前的形式看,业界有从 Lossless RDMA -> Lossy RDMA 转向的趋势,目前国内看到的阿里已经大规模部署Lossy RDMA,字节去年也发布了他们自己的Lossy RDMA方案,UEC里的UET也是定义在Lossy以太网中,现在MRC又拱了一把火。
在论文中,MRC把应用层的多路径(1 collective 拆多 QP,每 QP 经 ECMP 一条路径)下沉到transport层,对应用透明。而且把大量网侧的功能下沉到NIC,完全由NIC来完成。虽然规避了一些问题,但也带来了tradeoff,使应用场景受限。而对于网侧来说,除了要支持SRv6和Packets Trim外,就是傻大快了。当然决定架构走向的往往不是技术本身。
注:以下纯属个人分析,很多内容是根据论文推出来的,权当自己的阅读笔记,留作日后 review。理解难免有偏差,若有错漏之处,恳请留言指正,不胜感激。
论文原文:
完整阅读
5 5 月, 2026,由 frank 撰写
架构概述
之前使用过chatgpt和claude协助写过一些测试脚本,比如早期的:RDMA测试脚本 by ChatGPT?! ,后来优化的就没更新在blog中了。以至于后来研发的同事帮忙优化的测试脚本,虽然目前可以达到一定需求,但python精度太差,都是ms级精度控制,效率不是很高。因此需要一套高性能RDMA测试脚本,满足不同场景下针对交换机的测试需求。目前看上去使用openmpi来控制perftest的思路比较合理,而且有的用户也在使用类似的方式,所以就尝试走这条路。以下是五一期间跟claude合作开发的测试系统,里面很多细节还有待完善中 。
设计思想
本方案采用 MPI 指挥 + perftest 执行的分离架构:
MPI(mpi4py) :只做”指挥官”——进程启动、全局同步(Barrier)、决策广播(Bcast)perftest(ib_write_bw) :做”士兵”——真正发送 RDMA Write 流量,由 HCA 硬件直接执行流量控制 :通过 SIGSTOP/SIGCONT 信号(training 模式,毫秒级突发)、perftest 内置 rate_limit/burst_size(storage 模式,微秒级突发,但并行打流时机会错开)、或两者结合(sync_burst 模式,微秒级突发,同步并行打流)
完整阅读
25 1 月, 2026,由 frank 撰写
上一篇总结了SONiC Switch Telemetry的方法:Sonic Telemetry Deployment ,由于测试RDMA时不仅需要监控交换机,还要监控服务器,因此此篇就是在原有架构基础之上融入Server测的相关监控。Server测主要通过node exporter采集本地信息,然后吐给Prometheus,本地信息主要包含如下信息:
支持RDMA相关的各种硬件Counter信息(CNP/ECN、重传、QP 状态等),专有计数
支持Ethtools中Per-Priority相关的counter,这个是通用计数
另外更新之前自动生成配置的shell脚本,覆盖服务器这边的配置。
完整阅读
10 1 月, 2026,由 frank 撰写
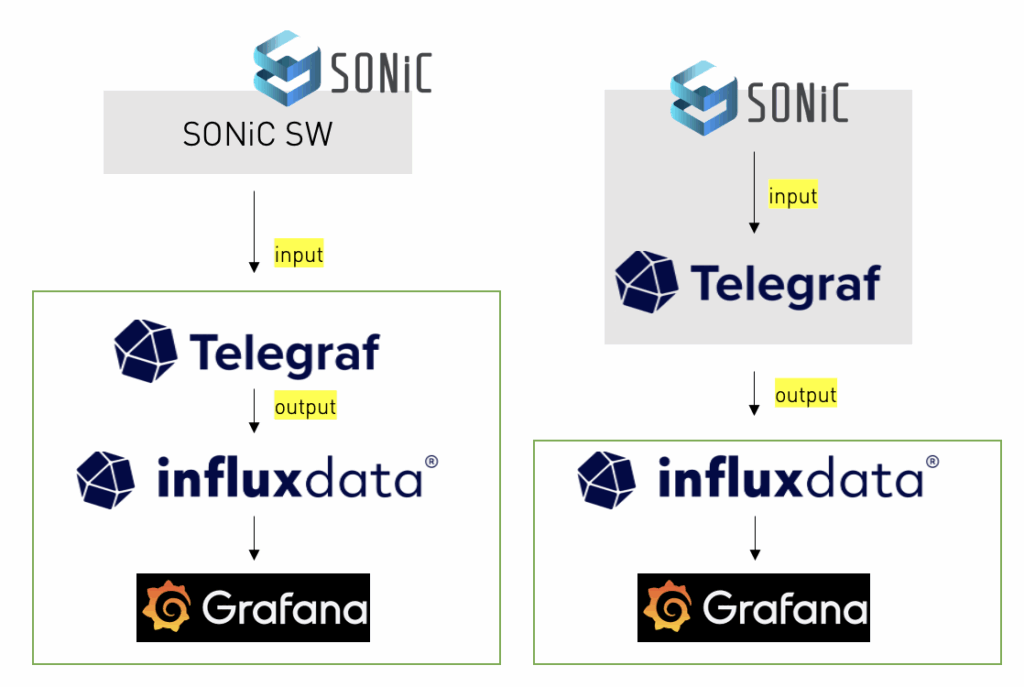
之前在老东家做TME时,整理过IOS XR相关的Telemetry,比如:Telemetry Solution Demo with IOS XR ,也研究过 Telemetry Receiver by UDP+KV-GPB 。但对Sonic Switch一直没搞过,一是Sonic是基于redis数据库的,对openconfig支持的不好,另外之前用的思科开源的pipeline很久没更新了,应该是被废弃了。2024年整理过Sonic + Telemetry,那时用的是Telegraf作为中间件,而且为了灵活,在SONiC上安装Telegraf的container,但这个方案真正实施起来有些繁琐,不如直接在服务器上部署Telegraf,当时很忙,也没时间整理,时间长了,细节就忘记了。
这次正好又面临可视化需求,因此重新梳理了架构,这次不再使用Telegraf+influxdata,而是采用gnmic + prometheus的方案,gnmic是openconfig开发的,而且在github上更新频繁 。代码内容,可以查看:https://github.com/yongpro/sonic-telemetry
另外更新了Server Telemetry,具体看这篇总结:Server Telemetry Deployment ,是在现有架构基础之上扩充的。
注意:整个方案会不断迭代和优化,因此文章原始内容我可能不一定会跟着优化而修正,我只是给自己作总结。如果需要参考,请过完整个文档。另外部署Telemetry平台,建议在本地局域网,避免数据传输延迟导致数据不正确。
完整阅读
21 12 月, 2025,由 frank 撰写
背景
之前一直在用群辉的synology photo,只能说还不错,但说不上优秀。因为查找照片不是很好找,不支持AI,外加最近为了让老婆也能直接自行使用otp,把home下面的photos挪到了根目录下,也就变成了共享照片。这个操作之前没操作过,我是直接用命令cp的,导致我之前编辑的人脸数据,以及相册数据都没了……要从1TB的照片和视频中重新把之前的相册聚起来,基本不太可能。所以就想看看是否有支持AI功能的个人相册,让我轻松找到想找的照片,因此才有了这篇文章。
经过查找,immich不错,比较符合我的要求,正好我还有一台老电脑没有卖,直接利旧了~ 我本想是安装黑群晖的,但经过对比后,果断直接linux + immich + gpu硬件加速了;这样除了把照片慢慢挪过去外,其他的一些非重要数据可以也都挪到老电脑上,老电脑直接装一个smb就可以满足我了,等群辉以后有更好的解决方案,到时再看是否回去。
磁盘规划
推荐分离系统盘和数据盘:
盘 格式 挂载点 用途 NVMe 256G LVM/ext4 / 系统 + Docker + Immich 数据库/缓存 4T 机械盘 ext4 /mnt/photos 照片/视频存储 1T 机械盘 ext4 /mnt/backup 备份或扩展存储
完整阅读